

In February, I presented a talk at the Sydney Microservices Meetup titled “Microservices at Tyro: An Evolutionary Tale”.
Microservices at Tyro
I wanted to talk mostly about things we’ve been doing with microservices at Tyro Payments over the last year, but also about the almost 10 years of practice with distributed computing that has led us towards what we’re doing today.
I’ve merged my slides and the audio from the talk into a video, which you can watch below. If you’re more the reading type, there’s a transcript from the talk beneath the video. My talk goes for 40 minutes and then there’s 20 minutes of Q&A.
The talk covers:
- Who is Tyro Payments?
- Why are we doing Microservices?
- Tyro’s Architecture History
- Current development in Microservices
- Tyro Microservices Practices
- Asynchronous Communication Strategies
- Helping Out Ops
- Microservices Technologies and Patterns
- Challenges we’ve been having at Tyro
- Microservices pre-requisites

Want to learn more?
 |
 |
 |
 |
Transcript
I’d like to start off just by doing a little survey. Who saw the title of this on Meetup and thought, ‘Oh that sounds interesting. I might learn something from it’? Just chuck your hand up if you thought something like that. Keep your hands up, I’m going to ask a couple of you what you thought you might learn. Sir?
“I thought that probably you process a lot of data and maybe you have better organisation of your microservices.”
Excellent. I think you had your hand up.
“I did. I thought I’d learn something about Tyro. I thought I’d learn, perhaps, just like a contrast, before and after sort of picture.”
Okay, thanks. Someone else? There were lots more hands up. Brilliant.
“I thought maybe there would be some lessons to be learned from challenges that you guys went through. So I think that’s worthwhile.”
Yep, excellent. Thanks. So I’ll cover most of that. I don’t think I’m talking much about data unfortunately but maybe someone can come and do that in the future.
So, I love surveys. I’m going to be talking about this stuff. [See list at top of blog.] I’m going to go pretty fast. So, lots of stuff, I’ll go shallow and there’ll be time for questions at the end if you want to find out more about something.
Tyro Payments
Surveys. Can you put your hand up if before this talk was announced you’d never heard of Tyro Payments? (About half the room put their hand up.) Ok, thanks. And put your hand up if had heard of it before. (The other half puts their hand up.) Thanks. And now, just keep your hand up if you’d only heard of us before because a recruiter contacted you. (No one puts their hand up, but most people chuckle.) Ok, I’ve got to have a word to our recruiter because they should have talked to all of you.
So, even though you may not have heard of us, you might have actually used our services. We do EFTPOS. These are some of our unique looking terminals and our custom receipts.



There’s a lot of them around the place. Often people who join us, a couple of weeks after they’ve joined us its like, ‘Oh, my doctor uses Tyro. I never even realised I’ve been using it all this time.’
Acquiring / Payment Processing
What Tyro does is, in the finance industry, technically called acquiring. You might call it payment processing. And so, basically what we do for merchants, who are customers,
the people who pay us money, we provide them connections to a whole bunch of different ways for their customers to pay. So we connect them to international card schemes, the domestic EFTPOS network. We also connect them to Medicare and private health funds and some gift card partners as well.
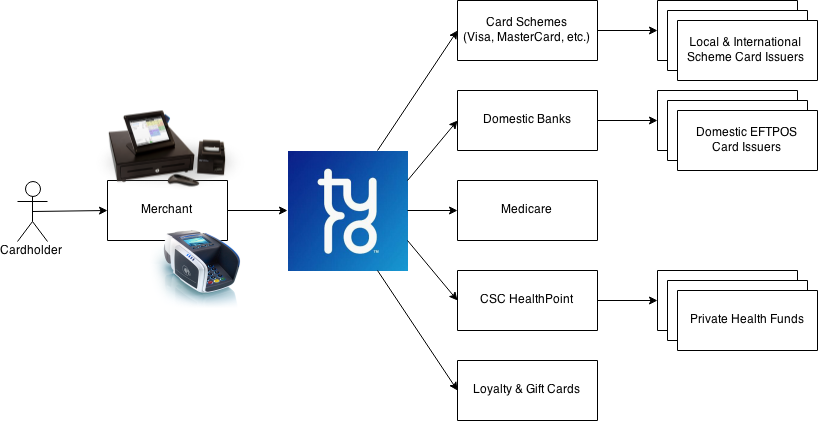 So we’re writing a lot of stuff there. There’s kind of real time connections and there’s batch processing and integration with the RBA [Reserve Bank of Australia], because that’s how the money moves around. We don’t make the hardware but we do write the application software that runs on the terminals. We don’t write point of sale software but we do integrate with hundreds of point of sale software venders.
So we’re writing a lot of stuff there. There’s kind of real time connections and there’s batch processing and integration with the RBA [Reserve Bank of Australia], because that’s how the money moves around. We don’t make the hardware but we do write the application software that runs on the terminals. We don’t write point of sale software but we do integrate with hundreds of point of sale software venders.
Is Tyro a Bank?
In case you’re wondering, we’re not a bank. We’re a financial services company. We’re not allowed to take money on deposit so while we process millions of dollars each day that money all comes into our system then we pay it out straight away again.
Why Microservices?
So, I’ll cover, just briefly, why we do microservices. This topic’s been done to death but I think that if you get our view, that might help with some of the things I’ll talk about later.
Why Microservices? : Business Agility
So, I think the key thing is business agility. So we all know about software agility these days, the opportunity for software teams to kind of change direction quickly and experiment with new things. And business agility is the same thing but for the business. You want to enable the business to be able to try new things, to be able to move into new places quickly. I think that’s the primary reason that we’re doing microservices. If you want to know more about business agility, I can recommend this book called The Phoenix Project. It’s about DevOps and the theory of constraints but it’s really about the same thing, about getting business agility into a business.
Why Microservices? : Decoupling
It’s about decoupling, microservices is about decoupling. I think that’s the main technology advantage. Decoupling things makes change less risky and also makes change easier to deploy.
Why Microservices? : Autonomy
Decoupling also leads to service autonomy and we think about service autonomy because we want the services we build to be responsible for achieving their business task. In general, to do that, they need to be able to integrate with as few other services as possible. So decoupling and autonomy work together.
Why Microservices? : System Resilience
And then, that plays into system resilience. So once you’ve got a system that’s built of autonomous services, your system should become more resilient because if part of that system goes down, the other parts, in theory, should be able to continue doing their job.
Why Microservices? : Productivity?
Is it about productivity? Maybe yes. Maybe no. I think with microservices, you end up with smaller code bases and that’s going to be a good, productive win for your developers because, you know, the business software they’re working with will be easier to understand. But then, you’ve also got the distributed computing aspect which means there’s a lot more things to consider that if you’re putting everything into, you know, one memory space you wouldn’t have to think about at all. So, I think there’s pluses and minuses here. Perhaps long term, you’ll end up with a productivity gain from microservices. If you’re hoping to do microservices for some productivity gain in the short term, it’s definitely not what you’re going to get.
Why Microservices? : Silver Bullet
It’s of course not a silver bullet. It’s to solve a set of problems but it brings a set of problems with it that are different.
Why Microservices? : Hype
And microservices are most definitely about hype. Personally I think, as an industry, we’re probably at the peak [of the Gartner Hype Cycle].
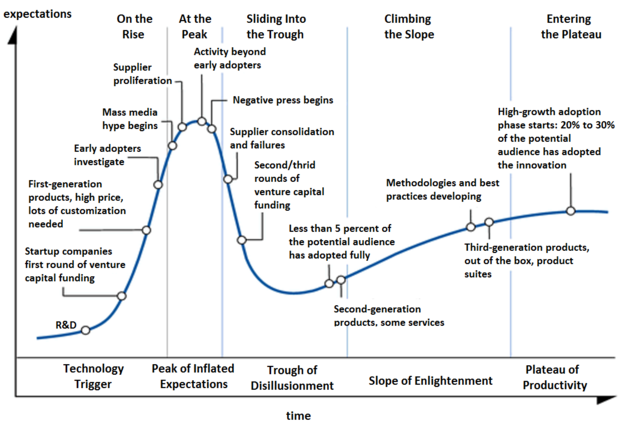 We’re starting to see the books and the blogs flow out and everyone talking about it. At Tyro, I’d say, we’re seeing some challenges and so we’re kind of on the way down the trough there. We know there’s lots more challenges to come. I wouldn’t say that we’re put off at all. We’re going to keep pushing through to that plateau of productivity. But I think it’s interesting that different organisations and even different teams within an organisation can find themselves at different points in this hype cycle. So you might find one team’s really only just getting starting with microservices and they’re still excited and doing new things while some other team might have been doing it for a year and they’ve found all kinds of problems and they’re kind of down here and basically bitching about it at lunch time. But you can use that to your advantage too. If you can get those teams talking, they can learn things from each other so maybe some of the vitality of the people who are still hyped can play off onto the other guys.
We’re starting to see the books and the blogs flow out and everyone talking about it. At Tyro, I’d say, we’re seeing some challenges and so we’re kind of on the way down the trough there. We know there’s lots more challenges to come. I wouldn’t say that we’re put off at all. We’re going to keep pushing through to that plateau of productivity. But I think it’s interesting that different organisations and even different teams within an organisation can find themselves at different points in this hype cycle. So you might find one team’s really only just getting starting with microservices and they’re still excited and doing new things while some other team might have been doing it for a year and they’ve found all kinds of problems and they’re kind of down here and basically bitching about it at lunch time. But you can use that to your advantage too. If you can get those teams talking, they can learn things from each other so maybe some of the vitality of the people who are still hyped can play off onto the other guys.
Tyro Architecture History: Distributed System Evolution
So, Tyro’s architecture history is interesting. We basically have a distributed system that has evolved. So, just before I joined, everything in Tyro was in one application. That was the server for the terminals, the public facing merchant portal, the private back office web portal, the batch processing, the integration with settlement systems all in one application. So some of that had been separated out and, at the time I joined, w were in the process of separating the other things out. We were actually doing that for regulatory reasons. We wanted to get PCI-DSS certified and we had to have an N-tier architecture in order to protect our systems. That was the driver at that point. But we continued adding new features and as we added new features to the system, it seemed to make sense, if there was a big new responsibility, to put it in another application rather than throw it in with all this other stuff. So we did that and that worked well, though we did often, we had one component that stored data and did batch processing. So we tend to put kind of the real time aspects in their own new little server but then we’d throw all the data in one place as well. And that place has become our monolith and it’s still around today. I’ll talk about that a little bit.
But we’ve definitely enjoyed the benefits of that decoupling that we did. So for example, at one point we went from having one transaction switch in one data centre to having four transaction switches across two data centres. And we were able to do that pretty simply because it was already decoupled from the batch processing. We didn’t have to think about how to do that separation or how to do redundancy of the batch processing or that kind of thing. So it’s definitely had benefits for us over time.
Tyro Architecture History: The Legacy Monolith
Like I said, we have a monolith. I think we’ve done an okay job of keeping it from being a big ball of mud. There are definitely bits that are mud but there’s lots of bits that are kind of in really tight components and have API’s that kind of separate it from the other components and that kind of stops things from getting too linked into each other in the same way that microservices is meant to by having those distributed interfaces.
Tyro Architecture History: Breaking Our Monolith: The Risk-Based Approach
We’re actively splitting stuff out of that. I won’t talk much about because that’s a whole other talk and there’s other people better qualified than me to do it. But I will say one thing about it which is that we use a risk-based approach to decide what to split out of that monolith. So, we looked at the monolith and we said, ‘If this monolith fails, what will the business be most annoyed about that that bit isn’t working? You know, what is the thing that is the biggest threat to the business if this thing isn’t working?’ And so we identified that component. We said, ‘That’s the thing we’re going to pull out first.’ We’re going to pull that out so if the monolith fails, that thing can still do its job because that’s the most important thing. And that’s actually been really good because when we say to the business, ‘We’re going to do some refactoring, we’re going to do a big project, we’re going to change the software and again it’s going to be the exact same thing.’ They’re like, ’Huh?’ But if we can say, ‘At the end, if a big part of our software fails, we’ll still be able to do this important thing.’ They’re like, ‘Ah, ok. I see the value in that. You know, we’ve got this thing on our risk register that’s right up near the top right and you’re going to kind of bring it down a bit.’ You know? Points for that. So if you think about splitting the monolith, think about how you can get a business advantage out of that and not just a technology advantage.
Microservices at Tyro
Over the last 12 months, we’ve become much more aggressive about how we are doing microservices and in particular how we are avoiding putting new stuff in that monolith. So, if you kind of suggest putting anything in the monolith you should expect for people to come at you with clubs and take you down. The result of that has been that we’ve deployed 14 new services to production in the last 7 months, so on average about one every two weeks. And we’ve got another 18 in our pipeline. Hopefully, we’re getting more rapid at deploying them so it’s not going to take us another six months to get them out.
Microservices at Tyro : Architecture (The Gist)
I wanted to show you our architecture but unfortunately the VP of Operations didn’t really want me to take a map of our system and put it in the public domain for people to figure out how they can get in and have a surf around. Not that they should be able to do that. All kinds of protections, but you know, defence in depth, he didn’t want that public knowledge. But here’s a fake architecture I made together with the assistance of my 5-year-old. He placed some of the arrows, just to make sure it was completely random.
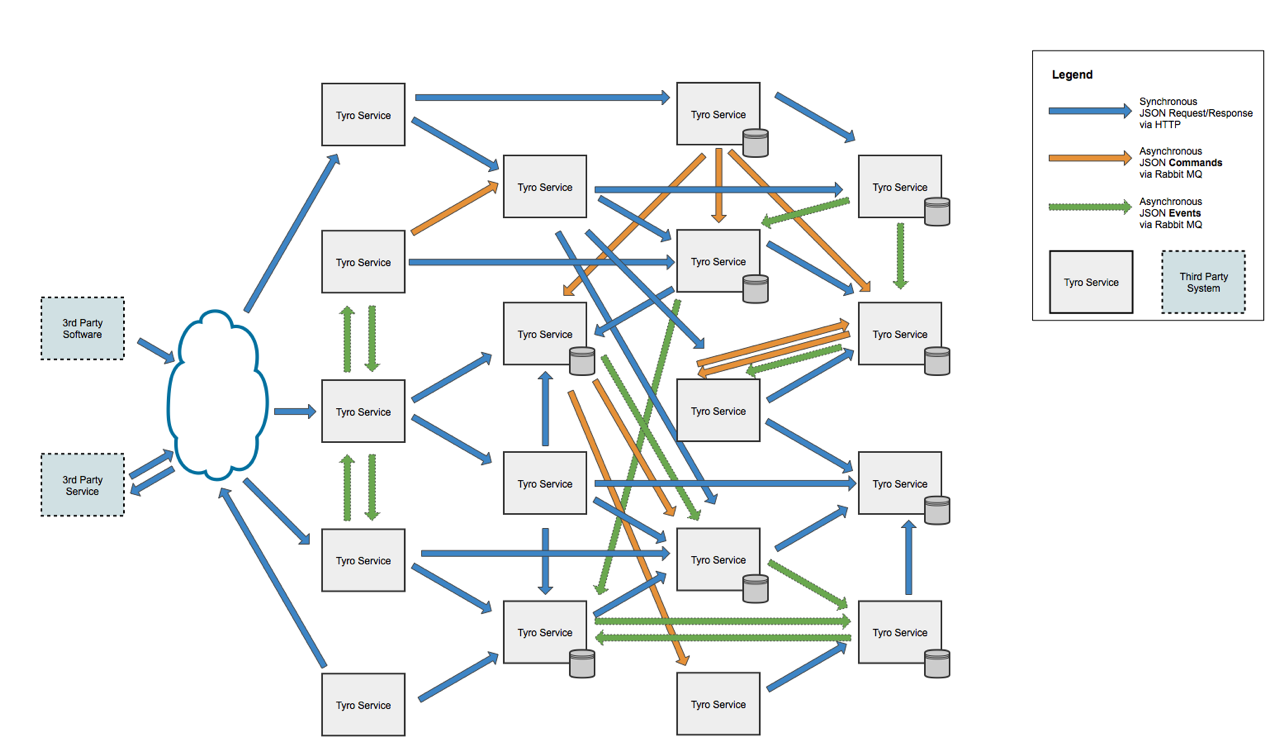 So it’s got a similar number of services to what we’ve been building over the last 12 months and a similar number and type of connections. So, you can see there’s things connect to the internet and third party services, lots of stuff going around with REST, we’re also using RabbitMQ for asynchronous communication. And we do that in two flavours, the orange ones are things we call commands, so that’s basically, you know, this service telling that one to do something but it’s doing that asynchronously. And the green ones we call events. So that’s basically a service saying this happened in my domain and other people can listen to that and it doesn’t know who’s listening or what they’re going to do. It’s a broadcast essentially.
So it’s got a similar number of services to what we’ve been building over the last 12 months and a similar number and type of connections. So, you can see there’s things connect to the internet and third party services, lots of stuff going around with REST, we’re also using RabbitMQ for asynchronous communication. And we do that in two flavours, the orange ones are things we call commands, so that’s basically, you know, this service telling that one to do something but it’s doing that asynchronously. And the green ones we call events. So that’s basically a service saying this happened in my domain and other people can listen to that and it doesn’t know who’s listening or what they’re going to do. It’s a broadcast essentially.
Another thing worth mentioning at this point is this is a logical diagram, so we run everything redundantly. Like I said, we’ve got two data centres so every service on this thing is running at least two instances in production. If it’s really important, there’s probably four. So that can make things kind of complex. We also deploy this software every two weeks and anything that gets changed, every two weeks, we release it and put in production and we do that during business hours. So we have kind of some design constraints. We do that intentionally. We’ve designed the system so we can upgrade it during business hours because Ops people are awake and if something goes wrong, Devs aren’t going to get woken up to fix it.
Microservices at Tyro : Service Anatomy
What does the Tyro service look like? Well, it’s going to be pretty boring to some people. Almost everything’s written in Java. Almost everything is on top of Spring. We’re deploying on Jetty. We use the Metrics library written by Coda Hale, now part of DropWizard. If we’re doing REST stuff, we’re using Spring MVC to implement that. We’re using Rabbit MQ to do messaging. If we’re talking to a database, it’ll be Hibernate or JPA. And we build all of those things with Maven. I’ll cover some of those a little bit. I’ll talk a bit about the Maven stuff.
Microservices at Tyro : The Size Question
I want to talk about size just briefly. Some people will say microservices is about having aggressively small applications. Personally, I think lines of code is a terrible measure of what a system is doing but I thought I’d show it to you just in case you’re interested.
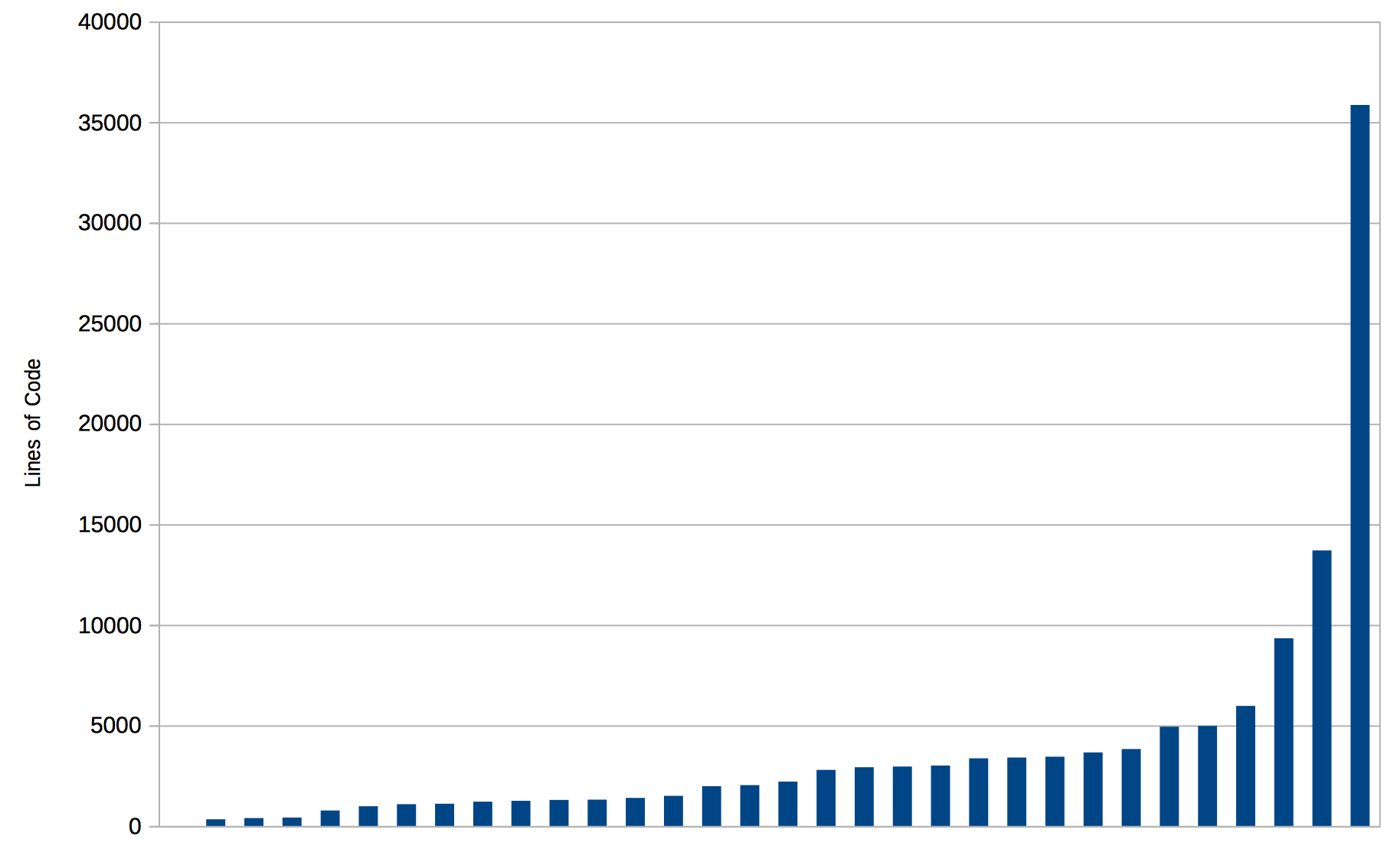
So this is just the things we’ve made in the last 12 months. The number of lines under src/main, so they’re not necessarily Java. There’ll be Java in there. There’ll be import statements. There’ll also be properties files, Spring configuration, all kinds of things. The one at the end is a web application that someone has imported JQuery and Twitter Bootstrap in as source. The majority of that is not actually our code at all. So the median here is somewhere around 2,500 lines. You can see most of them are less than 5,000 lines.
But I think when people are trying to talk about that, what they’re really trying to talk about is complexity and I thought maybe a better way to try and talk about complexity would be the number of classes in an application.
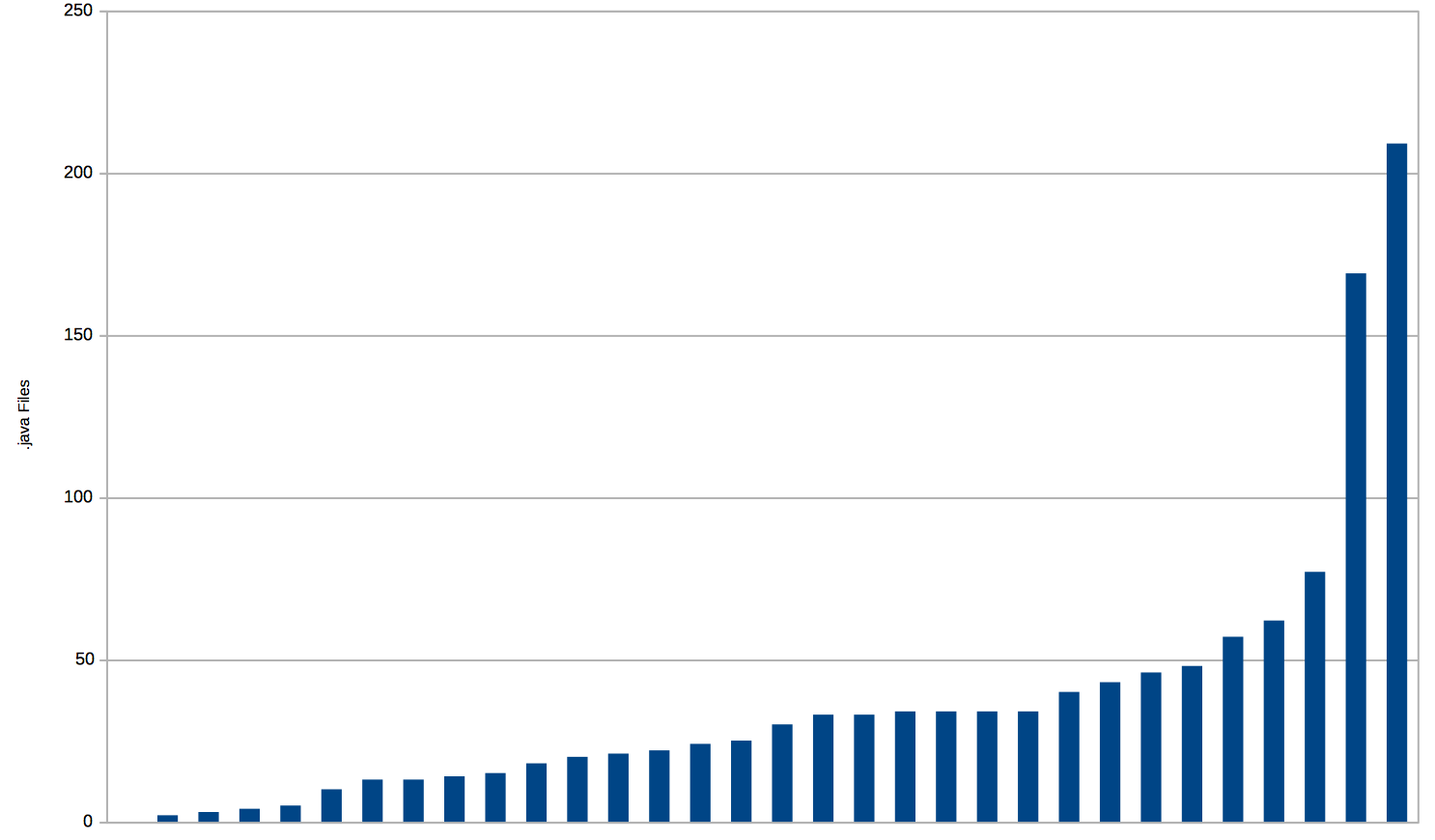
So this shows the number of .java files in each thing. You can see the majority of them are under 50 files and the median is somewhere around 25 or 30. So if you organise your code well and we do, think about maybe about six packages within a service and about five classes in each of those packages. So if you think about opening up a code base and you see six directories with five files in each that’s a pretty simple thing. You’re going to be able to understand most of that in half an hour and surf your way around and figure out the whole thing.
Some people might look at this and think, ‘Hey that’s not microservices. Microservice means your whole service fits in one file and you can print it out on an A4 page. That’s what micro really means.’ And maybe they’re right, maybe they’re not. I don’t really know. But I think context plays into that. We’re in a financial services environment and that means everything has to be guaranteed. You also have to guarantee that nothing gets done twice. You also have to audit absolutely everything that happens and we’ve designed pretty much everything for 100% uptime. So all those non-functional requirements end up as code, as you know. So, you might be writing a website with web services and you don’t have to think about any of those things and you can write your whole service in a page and it’ll all work brilliantly. But for us, life is a bit more complex. Having said that, there are a couple of things here that are only between two and five classes in the whole service. There’s actually one here that has zero source files, zero Java source files and that’s a service in production and running. So the whole thing is bringing libraries and wiring them together with some configuration that does something useful and runs in production.
Tyro Microservice Practices :
So I’ll talk about some practices now. We’ve got nine teams working in this microservices environment. So, it’s important to have some rules and guidelines and practices and things like that. Sometimes those things are there to protect us. Sometimes those things are there a strategy to win. And they’re all kind of there as a way to keep the team keep moving together in the same direction.
Tyro Microservice Practices : 1 Artefact = 1 Primary Responsibility
One artefact is one primary responsibility. So, this is, you know, if you’ve heard anything about microservices, you’ll have heard about this. And the way we’re cutting things up is by business responsibilities. So, we’re not trying to create, you know really generic reusable services like a unique ID generator that you call over the wire or something like that. We’re cutting things up by business responsibilities. So, if that things running but itself, it’s going to do something useful as far as the business is concerned.
Tyro Microservice Practices : Artefact Name = Responsibility
Artefact naming is really important and we name them after our responsibilities. So the rule we go for is that the name of an artefact should answer this question: What is this artefact responsible for? So if you say ‘What is this artefact responsible for?’ and then you say the name of the artefact it should accurately answer the question. So I’ll give you an example. This is just one I made up: Private Health Commission Payment Reports. So it’s pretty clear. What’s it responsible for? It’s responsible for private health commission payment reports. Now, on the other hand if you just called it Commissions and said ‘What’s it responsible for?’ you don’t know. Is it responsible for paying the commissions, receiving commissions, does it report on them or does it actually action them? You can’t tell.
Something else we do is we actually avoid words like ‘service’ and ‘server’ and ‘application’ because they can kind of tart something up without adding any information so “Commissions Service” sounds a bit better than “Commissions” but it doesn’t tell you anything else so we don’t put words in there like that.
I think I’ll give some advice if you’re making services, is to take the name of the service you’re making and go to someone who knows nothing about what you’re working on and ask them what they think the responsibility of the service is and if the answer they give you doesn’t make sense, maybe you need to think about the name of your service again.
Tyro Microservice Practices : Data Ownership is Essential
Data ownership is essential, I believe, in microservices. So, data needs to be owned in a single place. We don’t integrate any services through a database and we don’t let two services have editable versions of the same data. They don’t have editable versions of the same data.
Tyro Microservice Practices : Data Duplication is Okay
At the same time, data duplication is okay. So it can actually be really good to cache a small amount of data from another service in your service because that is an enabler for autonomy. If you need that bit of data to do your job, but you need to talk to the other service to get that data, then you’re creating a dependency at runtime. So, if you cache that data instead, you can be more autonomous.
Tyro Microservice Practices : Data Duplication = Eventual Consistency
There’s a catch though and that is that if you’re doing that caching you’re going to end up with eventual consistency within your system because you’re probably going to get that data over asynchronously. So, sometimes, if the network’s not working or that service went down or whatever’s happening, your data’s going to be out of date. So, if it’s important for your service to have the absolute latest data, you can’t do that caching, you have to go over and get that latest thing from the source, the place where it can be changed, where it’s be owned. Doing that makes your system less resilient because you’ve created a coupling at runtime. And at that point I say, ‘Hello, CAP Theorem,’ because it’s not exactly CAP Theorem, you’re not running a distributed database but you have made a decision between consistency and availability. So, if you’re happy to have a cached bit of data that might be a little bit out of date, then you’re sacrificing your consistency for some availability. But if you need to go to that source of truth, you need the consistency, then you’re sacrificing the availability. So you need to think about those things when you’re thinking where’s data going to live and how am I going to access it.
Tyro Microservice Practices : Common Communication Methods
We use common communication methods, something pretty much everyone recommends. So we have a small number, basically the REST and the Rabbit is all we do. We have common libraries that make it really easy for people to use those things and they include some of the patterns that we do around redundancy across multiple servers and things like that, so it makes it easier for people to get things right.
Tyro Microservice Practices : Shared Architecture Diagrams
We have some shared architecture diagrams, so you can see the system gets pretty complex pretty quickly. The diagram doesn’t actually look like that anymore because it got too complex so we split it out into ten different diagrams based on different features of what we’re building at the moment. But we allow people to go in and update the architecture so that everyone can see where their system is in this whole system and understand how the whole parts fit together.
Tyro Microservice Practices : Artefact Briefs
Artefact briefs are another tool that we have for people to help other people understand how the systems working. So, an artefact brief is a one page summary of a service. So, it lists its responsibilities, just in bullet points, you know, a couple of lines. And it also talks what it stores in that service and also who it connects to and usually for what reason it’s connecting to it. If it’s got any special security requirements like if it’s encrypting certain data, it’ll do that as well. It also lists the developers that originally created the service and the reason it does that is because there’s not all the information on that page. So, if someone from Test or Ops wants to talk to the people that created that service, they can go to this page on Confluence and say, ’Ah, I should go and talk to this team and I can get some answers.’
Tyro Microservice Practices : Parent POMs, Archetypes and Scripts
Parent POMs, Archetypes and Scripts. So, we’re using Maven. We’re using Parent POMs so that we don’t have massive build files everywhere that, you know, diverge from each other. Instead we define most of our build in one Parent POM and the POMs for our actual artefacts are quite simple. We define everything in one place. So lots of our builds are standardised. The archetypes and scripts pretty much allow us to create a new service in a couple of seconds. So, the archetype will create an application that has everything you expect in an application. We put the port numbers in as part of the script so the thing can run up instantly and it’s also put into source control and Jenkins Continuous Integration. So, within a couple of seconds, the team can make a new service and it’s building on Jenkins successfully and they can start adding code for it do something useful.
Tyro Microservice Practices : Scrum of Scrums
Scrum of Scrums. So, we’ve got a project at the moment that has six teams of seven people and they’re all coordinating quite a lot. So, in order to ensure we coordinate well, we recently started doing Scrum of Scrums meeting, so the team leaders of the teams just meet twice a week to chat about what each team’s doing and get things together. We don’t actually practice Scrum, we practice Extreme Programing but Stand Up of Stand Ups never quite caught on so we just call it Scrum of Scrums.
Tyro Microservice Practices : Internal Microservice Guidelines
We have some internal microservice guidelines. So, it’s unrealistic to expect that everyone on your team is going to get excited about microservices and they’re going to go home and read a microservice blog every night for the next three months and become an absolute expert. There will be people who do that. There’ll be lots of people who don’t and the only thing they’ll know about microservices is what they heard in the iteration planning meeting and what they hear from their pair or whatever it is. So, in order to make sure everyone’s on the same page, we made a one page document that says, ‘This is what our guidelines are for microservices here at Tyro.’ You know, between people reading lots of blogs you might even get people who are both experts but have different opinions, so having some kind of guidelines that everyone can agree upon and move forward in the one direction is a really good idea.
Asynchronous Communication
I want to talk a little bit about asynchronicity, if that’s a word. Asynchronous communication is the grease that makes microservices work. Without it, you’re kind of making, you know, a kind of monolith that’s distributed and gets all coupled together. So at YOW!, Martin Thompson said this, “Synchronous communication is the crystal meth of distributed software.” And his way of explaining that was that it’s easy, it feels good, but it’s really bad for you in the long run. And why is it really bad? Because of a thing called temporal coupling. Temporal coupling is basically services depending on each other in time. So, if your service is waiting for another service to respond, it’s not autonomous. That means, if part of your system does go down, then lots of other parts of your system aren’t going to work and you’ve just kind of cut out one of the main advantage of microservices if you do that. So the advice I give to people at work is: if you can do it asynchronously, you should. That should always be your preference. It almost ends up that the only time you should do something synchronously is if a person or some other system that we don’t control is waiting for a response. Usually, when it’s a system that we control, we can change the design so that we’re not waiting or a response.
Asynchronous Communication: Distributed Transactions
The thing with is asynchronous is that distributed transactions end up coming in and basically you should avoid distributed transactions at all costs. And I’m not just talking about the standard XA transactions. Anytime when you’ve got two service talking to each other, and they’re both going to make a change to their data as part of that communication, that’s a distributed transaction and you need to avoid that if you can. So if you’ve got some sort of synchronous thing going on and you’ve got data that needs to be updated in more than one service, typically the way we would address that is by having all the data committed to one of those services and then the data that needs to end up in the other service is distributed over to that asynchronously.
But then when you go asynchronous, you get some problems as well. With asynchronous communication, what you often end up with is on the receiving side it’s got some business state and that’s going to change. But then you’ve got some queue states somewhere. If you’ve got messages moving through a system asynchronously, there’s always a queue state which is what messages have been delivered. So having those two things can play problems. There’s two ways to approach it that I’ve thought of. I haven’t practised both of them but one is a feed strategy. So, that means you will get on the thing that’s producing a message you’ll be producing a feed and that feed, while it keeps growing, it doesn’t have any queue state in it because anyone who wants to read the feed can read the feed. So it’s up to the client to keep their own queue state and because the client has their own queue state and they’re changing the business state, you’ve got those two bits of state in the one transaction. So, feed strategy is the queue state and the business state are both in the same place in the one transaction so you don’t have it distributed.
The other way to do it is if your queue state is on one side and your business state is on the other, what you need to do is your business change needs to be item potent. So, if it runs a second time, it’s going to do the same thing it did the first time. And often that just translates into, you need to do duplicate detection of message that are coming in. So, if the same message gets delivered twice, that’s fine. So then you can commit the business change, and on the queue state side, you only commit your queue state change after you’ve guaranteed that the business state change has happened. And then you can deliver that message multiple times if you want and know that it’s safe to do that.
Helping Out Ops
So, it’s really important to help out your Ops team because when you start doing microservices, they’re going to have a heart attack. So, here’s a bunch of things we’ve been doing.
Helping Out Ops : Deployment Control
This one’s a bit old, before microservices but it’s definitely helped with giving us some leverage. So, in the good old days, Ops used to upgrade our software, they would ssh in the production boxes. They’d scp the WAR over, they bring Jetty down, they’d copy the new WAR into the right place and they’d bring Jetty up. And we had ten applications and that was all fine. Eventually, we got to 100 applications and you can’t be doing that every two weeks. It doesn’t work. So, we built this thing called Deployment Control. It’s basically a web application that operations can log in to and they can see all of our production infrastructure and they can click into any VM and see what software’s on there. They can just click and say, ‘Upgrade this software to the latest version.’ So when they do deploys every two weeks, they basically don’t’ touch ssh at all. They just go in to this web app and they just click a button and it upgrades. So that way, we can upgrade 100 things every fortnight and they’re just kind of clicking. We even put an upgrade all button on their so if there’s ten things they just [pop] and it all goes. Sounds dangerous, yeah, but it’s been working.
Helping Out Ops : New Artefact Checklist
New artefact checklist. So the first few microservices we pushed in were terrible. They were terrible from the point of view, we built them and then we took them to Ops and said ‘deploy this’ and they’re like,’ What is this thing? You didn’t even tell us you had a new artefact. We usually prepare for these things three months ahead.’ We’re like, ‘Oh yeah. That’s not great, is it?’ So over time we developed this checklist. It’s basically a list of things that the Dev team should be doing and following up before a new artefact can be called ready to deploy and then fully deployed. One of the things that’s on that checklist really early is a meeting with Ops and it’s actually got a defined agenda on there of about 15 items around where it’s going to be hosted, what firewall changes you need, is it talking to Rabbit, is it offering REST, is it exposed to the internet, what security does it have. All kind of things. So we use that to make sure we’re getting the requirements form Ops that they have right up front rather than getting something almost ready and then them saying, ‘Oh, no you can’t deploy that. Split that thing in two because the design doesn’t work.’
Helping Out Ops : New Artefact Pipeline
We’ve got a new artefact pipeline, it’s basically just a Confluence page but it means that everyone can look at this page and see what services are being developed, what ones are in the midst of being deployed for the first time. Are there things that are blocked and why are they blocked? Who’s responsible for getting it unlocked? All on one page so that allows teams to see what their things are up to and it allows management to see are there blockages in the system that we need to address.
Helping Out Ops : Monitoring
Monitoring’s really important, super important when you’re going to do microservices but you also don’t want to spend too much time on it. You don’t want developers putting loads of time into monitoring because a lot of the time you’re doing the same things in each thing. So, we’ve got some common libraries of written and basically if you import these libraries and you’ve got a database, you instantly get monitoring through your database connection pool or if you’re using Rabbit, it instantly gives you monitoring for that. Whatever REST endpoints you’re talking to, it’ll find those and do monitoring and tell you whether they’re up or not.
We’ve also designed this thing in cooperation with Ops so that the services are able to tell the difference between a warning and an error. So for an example, if I need a REST service but there’s four instances of that and I know one of them’s unavailable, that’s a warning because I can keep doing my job. But if all four of them go down, that’s an error because I can’t do my job anymore and that translates into Ops’ world as, ‘Do I need to get out of bed?’ So, if something says warning, its like, ‘I got to fix that… in the morning.’ If something says error, I’ve got to get out of bed. And I think it’s really good when you’re thinking about monitoring and alerting, as a developer, to put yourself in the shoes of an operations person receiving an alert at 3 am in bed and thinking what information are they going to want? What kind of decision do they want to make? And how are you going to help them make that decision?
Technologies and Patterns
Technologies and Patterns. I’m just going to talk about a few things we’ve tried with mixed success.
Technologies and Patterns : Pact
Pact is a testing tool for something called consumer-driven contract testing and basically it allows you to do integration testing but kind of in a unit testing level. So rather than bring up multiple artefacts, you can do that in your unit test phase. And the way it does this is you’d do a test on your consumer side, it has a mock server and that mock server records what tests you did. Then you write tests on the server side, the producer side, and it replays what those expectations were that were recorded. So, you get a thing called test synchronisation where the expectations of the consumer are played on the producer to ensure it always does that. And the main advantage of that is backwards compatibility testing because you’re not limited to just playing the current expectations of your consumers, you can play the expectations of consumers in previous versions. So, if you’ve got old versions of the consumers running in production, you can play them as well and make that your producer is still handling old versions of consumers so you might have migrated your API but you can check that you didn’t break it for things that are still in production.
So the original Pact was written in Ruby by Real Estate Australia. There’s also a JVM version [of Pact] written by Dius. Both of those bring up a server during the test in order to work. We tried that for a while and didn’t really like to so we started writing our own thing based around Spring’s Mock MVC which is an in-process thing. Basically does the same thing as the other two but allows you to not bring up a server which makes them run faster. It’s quite convenient.
Technologies and Patterns : Client Libraries
Client libraries. They’re an idea we borrowed from Netflix. The idea is pretty much that you take the logic for connecting to your service and rather than putting that in each thing that is going to talk to this service, you put it in a library. And each of those things can talk to it. It’s got two benefits. You get code reuse and you also get separation. The services using the producer don’t actually need how they’re communicating with it. They get a Java interface.
Technologies and Patterns : Messaging / Event-Driven / Reactive
Messaging and Event Driven and Reactive stuff. So we’ve had mixed success with this. As you’ve seen, we’re using Rabbit MQ and we’ve had some serious issues with that in production. Split-brains, lost messages. Really hard to get back from those situations. We’re actually moving away from it at the moment. We’ve got a plan to move away from it. Some people are keen on putting another message broker in and trying some more. Some people are like, ‘Well, this message broker things not really our cup of tea anyway.’ My opinion is, it kind of puts a single point of a failure in a system that’s otherwise really well decoupled and I’m not sure that that’s a good idea to put in something that if this thing fails, everything stops or almost everything stops. So there’s differing opinion. There’s also differing opinions on, with event driven, should we be doing that as much as possible? So, should we have no Rabbit commands on that diagram? Should everything be events? Anytime something does something, it just broadcasts it and people react to events all over the place? So, there’s people who think we should be doing everything like that. There’s people who think there’s only a small number of circumstances where that’s applicable. That’s something we’re going to keep experimenting with I think and maybe we can share some more in another year when we’ve figured out what the best approach is.
Technologies and Patterns :RxJava
RxJava is another thing we’ve used a bit. It’s a Netflix library we’ve used for reactive streams. We use it in quite a few places and we’ve found that in some places it’s really useful and in other places it’s made the code really more complex than it needed to be. So, I’d say this is something that you should really check out and have in your tool belt but be careful where you use it because there’s good problems for it and there’s problems where it’s rubbish.
Challenges : Host Agnosticism
So host agnosticism. This is a bit of a funny one. It might actually be unique to Tyro. I don’t know. Our applications can’t be put on any host. The host has to have a particular host name. A configuration with that hostname is in our source control and tells it what to do. So sometimes those configurations per-host are almost identical, sometimes they’re really different. Put the same artefact on different hosts and it will do quite different things. So, it’s a historical phenomenon, not something we started doing for microservices but I just want to say, if you’re not in this situation, don’t get into it and if you are, get out as quick as you can because it’s a world of pain and it’s kind of hard to get out of.
Challenges : Deploy Frequency = Migration Wavelength
Deploy Frequency and Migration Wavelength is something we’re challenged with. So we have two weekly deploys, which is great, a lot better than a lot of people have but we also think it’s not good enough. So often we have to migrations because we’re changing systems all the time. And your deploy frequency becomes the wavelength at which you can do your migrations. So sometimes migrations have to be done over multiple deploys. You have to do step 1 this iteration, then step 2 and then step 3. And having a two week deploy means that migration can take up to two months and that’s something that has to stay on the team’s board and they have to remember to keep coming back to it and at the end of two months, they’re just going, ‘What is this thing again? We have to do this thing but I don’t remember why.’ Sometimes you don’t need to do it across iterations. You can do it in one iteration but you’ll end up with some kind of deployment constraint. So, we did this thing that’s not backwards compatible so, Ops can you remember to deploy this thing first and then that thing and then that thing because if you do it in any other order, we’re going to lose five million dollars or something like that. So those things are hard and hard things are okay but if you are doing hard things often, that’s not a good thing. So, we’ve actually got a team working on a continuous delivery pipeline for us. It’s going to get us away from that so our deploy frequency whenever the hell we want to deploy.
Challenges : Architecture Evolution Governance
Architecture Evolution Governance. So depending on where you work, this might not matter much at all. We’re a regulated entity so governance is a word that gets thrown around a lot. Our architecture evolves a lot and that’s a great thing. We embrace change but we have no official process governing how that architecture changes so anyone can just go and change anything. And sometimes that means that weeks or months down the line someone will go, ‘Which team added this connection here? Because that doesn’t really make sense and we need to back that out and do something else.’ So we’re thinking about putting a lightweight process around that so we can figure out how to get just a bit more collaboration on that before those decisions are made, not as they are being made.
Challenges : Client Libraries vs. Pact
Client Libraries vs. Pact: The great fight of 2014. So, Pact is great. It’s for testing your REST interactions. Client libraries have been beneficial. They’re for abstracting your REST interactions. So when you’ve got an abstraction but we also want to test that abstraction and the consumer layout, we end up with problems. So, that’s something that’s been hard. We’ve got some guys working on a solution to that now which is kind of interesting.
Challenges : REST Awareness
REST Awareness. So a lot of people don’t understand REST. A lot of people think, ‘If I send some JSON over HTTP that’s RESTful, you know. I’m using HTTP and I’m sending something I can read and that’s what REST is.’ So, they miss the whole thing about it being resource oriented and they end up doing RPC just over HTTP and that’s not a good thing. You know, if you’re all doing RPC over HTTP and you’re understood that’s what you’re doing, maybe that’s ok. But when some people understand REST and some don’t, you end up with this real mix of styles and it can be quite confusing. So, I just want to say, if you’re going to start using REST, make sure everyone on your team knows what REST is, what it means. I think even consider not using the term REST. I think saying Resource Oriented Interfaces is really a better description of what REST is all about.
Challenges: Pact for Messages
Last challenge, Pact for messages. So, we are now moving away from messages but we don’t have any backwards compatibility testing for our messages which is what we get from PACT. So, it’s something that’s on our to do list. We haven’t got to it yet. We’ve got some ideas on how to use Pact to achieve that.
Microservices: How Tall Do You Need To Be?
Lastly, I want to talk about an article that Martin Fowler wrote called ‘Microservice Prerequisites’. And, he started off with saying, ‘How tall do you need to be doing microservices?’
Microservice Pre-Requisites
And he put in these four things [“Rapid provisioning of services”, “Monitoring (Technical and Business)”, “Rapid application deployment” and “DevOps Culture”] and he kind of presented them as minimum for doing microservices. And, in discussing them, he put some concessions in. So he said things like, ‘It may not have to be fully automated to start with.’ But he wraps it all up by saying, ‘With this kind of set up in place you’re ready for a first system using a handful of microservices.’
So my problem with this article was he had this picture at the top and that’s what you kind of come away thinking is, ‘You must be this tall to start doing microservices.’ And I think all those things he had were good advice and you should certainly think about doing those things. I don’t want to suggest that you should build a system with 20 microservices and try to throw them into production and see what happens. But at the same time it would be really unwise to look at his list and spend a year building infrastructure to do that while delivering no business value.
So, what we’ve been doing at Tyro is continually shipping distributed software, that’s more and more distributed over time and learning from that and doing the things we need to do to deal with that like building deployment control so that ops can deploy things faster, coming up with the checklist so that we make sure that when we make heaps of new artefacts that they all get done right and that people understand what they are. So, yeah. I just want to say, you know, consider those things but don’t be scared by articles like this and think, “Ah, it’s too big a problem, we can’t try it.’ You can try. Build a microservice and get it into production and see what you learn from that and get some feedback and adjust your own process.
One Last Thing: Collection Code Ownership
I’ve got one last thing though. This is fun. Collective code ownership. So pretty much everything you’ll read about microservices says, ‘What you need is to be doing is you need to be dicing your services up by team. That team owns this service and that service and that team owns this service and that service.’ There’s even recommendations, if you’ve got a service that needs skills from multiple people you need to make a temporary team and commandeer some people and give them that service and then when it’s finished, you take that service and assign it to that team, something like that.
We don’t do any of that. We have collective code ownership. It’s an XP principal that basically says, ‘Everyone’s responsible for all of the code. Anyone can change any of the code.’ Now, within that, you’d be a fool to go and edit some service that you know nothing about without going and talking to the people who built it. You’d go and have a chat with them. You’d say, ‘I need to do this and you know, what are the best ideas’ but then once you’ve had a chat, you’ll go away and you can change that code. And maybe you’ll refactor some of the things they did and make it better and that’s part of the point of collective ownership is that people make things better over time.
So, I don’t want to say we’re never going to, you know, give up collective code ownership because maybe we’ll hit some problems in the future and we’ll get some feedback and go, ‘We do need to dice these things up.’ But, I feel like we’re being the rebels in that case, just basically anyone can change any service and that’s going okay for us at the moment. So there’s some microservice advice from other people which I advise you to ignore.
Microservices Adolescence
So wrapping up, Tyro’s been on a distributed computing track for a long time now. In terms of microservices though, I’d say we’re still pretty adolescent. We’ve learn lots of things but we’ve still got lots more things to learn. We try and stay informed and incorporate good ideas from other people. But we also sometimes ignore other people’s good ideas and just kind of forge ahead and see what we learn anyway. And we’re going to be doing lots with more microservices this year. We’re hiring lots of people this year so if you’re a software engineer or a tester or a systems engineer or a network engineer, please come and see me and get a business card because we want to get your resume and we want see if you’d want to come and work for us and work on some interesting stuff like this. Thanks very much.
Questions
Do people have questions?
“I know you guys use pair programming. How do you think that’s impacted on the development of using microservices and going down that path?”
I’m not sure how much I’d put that together with microservices but the thing I would say about paired programming is if you look at the XP values, things like communication, feedback, respect, simplicity, and look at all the other practices that are in extreme programming, pairing supports almost every single one of them and it’s a multiplier for those things. So, with paired programming, you get feedback two seconds after you’ve written a line of code. If you do code reviews instead, it’s going to be a week. Two seconds to a week, that’s a massive difference. You know, you look at lots of things, pairing increases all those things. Communications are another great example. So, I think some people think, ‘Oh, we won’t do pairing, we’ll get twice as much code out and we’ll still do kind of well.’ I think pairing really enhances lots of agile things so not doing it kind of divides the effect of your agile process. Is that an ok answer?
“Considering the restrictions that you put on the technology stack that you use for every microservice then using common libraries, aren’t you kind of closing the door to other languages that might allow you to solve a particular problem better … rather than forcing the same model using the same technology stack?”
Yep, good questions. So the question is, by using pretty much the same technology stack for every service we write, do we cut ourselves out of using a technology that might be better than some process than something else? I think the answer is probably yes. I think we’re not absolutely committed to those things but at the moment, things are set up really well to be able to a produce service that works like that quickly and get it in production. So, if we wanted to start writing things in say Ruby, well, our deployment process is built around Jetty and deploying WARs, so we’d need to do some work on doing that. And we could make that happen and the continuous delivery platform we’re working on is going to make some of that easier, so it’s really built around base images and what you’re going to deploy on top of that. So we might be able to have a Java version that makes it easy to deploy Java stuff and a Ruby platform that makes it easier to do that stuff. But at the same time, having lots of the teams working with the same technology can create real benefits. You know, this team solved a problem and five other teams get the benefits of it. So I think that’s a trade-off and we’ll continue thinking about that trade off. I think you make a good point. Some problems, you’re going to go, ‘Well, that really needs to be done with Haskell.’ Maybe we figure a way to do that when that comes. Heaps of people have said that. I don’t know if they’ve ever deployed it.
“I’m curious who owns all of the architecture processes. Who owns the decision to make a new service versus extend an existing one and so on?”
Yeah so, that was who owns the architecture and who can make a decision about changing it? At the moment, basically: the development teams. They’re given a feature to develop and they’ll sit with a product manager and they’ll come out with a bunch of stories for that feature and they’ll decide what changes do we need to make in order to make that feature. Do we need to change an existing service? Should we make a new service? And you know there’s kind of two types of features. There’s features that are a new business responsibility and that’s obvious. We’re going to build a new service. There’s other features that are kind of an enhancement to an existing business responsibility and its like, ‘Well, then you need to make a test.’ Does it require modification to an existing thing or is it a big enough kind of change that we should put it somewhere else? So that’s kind of the problem is that individual teams make decision. And that’s great. We love autonomy at Tyro. We love giving people the power to decide things by themselves but with a regulator asking how do you control these things?, that’s why we need to put a process around, not necessary stopping that autonomy, but making sure there’s governance that kind of, you know, checks that we have these rules about how the architecture can change and are we following those rules as decisions are made?
“I have a question about, do you have any orchestration in your services? Or did you just have simple services, no dependencies at all? Because sometimes there are people or organizations who have some kind of orchestration in their service as well. How do you deal with the need for orchestration?”
So, sometimes we have services which, to achieve their responsibility, need to do some orchestration. So, an example is we have a boarding service and it’s responsibility is firstly to collect information from an application and then once that application’s been approved, it needs to go and talk to five other services to say ‘provision this guy on five different services.’ So, orchestration comes in when it’s the responsibility of some service to conduct that.
“I have a question about what technology do you use for that orchestration?”
So that particular example, that’s a Java service. So, it’s already the thing that’s collecting information and basically they have done idempotent REST calls and tracking… there’s basically a state on that application in the database that tracks what it’s up to and it goes, ‘ For this state, I need to call that service .’ And if it succeeds, it updates the state to the next one.
“If you modify the version of existing services, how do you control the interdependency between the services and the orchestration? So you’ve got more complex services for each top, that sits on top of your simple services and there’s an interdependency between these services. How do you control this dependency? How do you say, ‘I’m going to have a release into production next week so these are the dependencies and we need to deal with these services as well.’ Do you have any control over that?”
So, I think you’re asking, ‘How do we know we need to update the other things?’
“Yeah.”
The answer is, we have automated scripts that do our release every two weeks. Anything that’s changed gets released and everything that’s released gets deployed. And we have a thing that generates a deploy script and that knows about the order of dependencies in terms of compatibility and so it tells operations to deploy them in the right order so that backwards compatibility maintained.
“So it’s more like a manual process?”
The deployment has a lot of manual steps in it but in terms of choosing what to deploy, everything’s deployed. If we changed it, it gets deployed.
“You’ve used the word idempotent a few times. I only found out what that meant last year. I also know a number of people and they only found out last year because I asked them. Maybe everyone in the room doesn’t know what that word means.”
So, I’ll try and simplify it. Someone can tell me if this is wrong because it could be wrong. It’s basically, I’m going to call something that changes state. If I call it twice, the state looks the same as when I called it the first time. So, as an example, if a transaction came in from a terminal, a second time, we wouldn’t pay the merchant for that twice. We wouldn’t debit the cardholder twice. We’d be able to recognize, we’ve already done that. We wouldn’t do it again.
“You talked about how you never share databases and how you never have one service going to another to get data. So basically you do replication everywhere?”
No. Sorry, I didn’t say we never have a service going to another to get data. We do that sometimes, particularly when there’s a lot of data to get or when there isn’t a time constraint. So if the thing you’re doing is asynchronous, then sometimes you’ll just go and get the data because no one’s waiting.
“There are certain types of data like customer that everyone needs so, do you replicate that as well, or … you will end up with some situations where you need this data instantly.”
Yeah, so, the answer is we make a decision about whether to replicate that in each scenario. Typically you’d do that if it was small. If it was one or two fields that you need and it’s something like customers, yep. You’re going to replicate that because if you’re going to rely on needing it, then you do it. If you need the whole customer object for some reason and it’s owned by something else, you probably wouldn’t replicate that because it’s just copying the whole database into your database and that doesn’t make sense. If you get to that point, you maybe need to think about, have you got that responsibility in the right place? If it needs all that data, maybe the thing that has all that data should be responsible for it.
“And if you decide to replicate, are you using Rabbit for that as well?”
Yes, we are using that at the moment.
“You mentioned that you never use distributed transactions so did you mean across services or within services as well?”
I think distributed has to mean across services. In my mind, that’s what I mean. When I say distributed, I mean two services. But we don’t use any official distributed transactions.
“I mean, there was a scenario you described where you write something into your database and then you want to publish that as an event so you then queue a message. So, if you do not have distributed transaction there then you might save to a database and when it’s time to queue a message it says failed?”
Yep. That’s exactly right. So the way we do that is basically everything we put on Rabbit, before we put on Rabbit we save it into the database and then we have a thread that’s pulling it out of the database and sending it. And that’s where we’re using that strategy I was talking about where it basically makes sure it gets an ACK from Rabbit before it deletes it from the queue. And if Rabbit has received it but doesn’t ACK, we might end up sending it twice. So, basically everything we send of Rabbit has to have duplicate detection at the other end. So, you’re right.
“Is it like a batch thing that’s running continuously?”
Yep. So we call that our async Rabbit sender. So when you want to send something on Rabbit, you don’t send it. You put it in the async Rabbit sender and it goes to the database and it comes back out onto Rabbit, to guarantee that it gets sent to Rabbit.
“One last thing. You mentioned feeds? Did you mean ATOM feeds?”
We haven’t done any feeds yet. There’s a team looking at it at the moment. I believe they’re looking at ATOM feeds. There’s some good talks on the internet about people using ATOM feeds to do that kind of stuff.
“So, my question is about how do you make management interfaces, contracts, between microservices? If you have a bunch of microservices and change one, do you update every other one? And how does everybody know what these microservices do? That you have this existing functionality? Any processes for this?”
Yeah, so I’ll take the second one first. So, how do people know what microservices exist and what they do? That architecture diagram is really the go-to for that. By looking at that, and having those artefact names that explain what each thinks responsible for, then you’re able to look at the system. You should be able to get a non-technical to look at our architecture diagram and they could explain to you what the system’s doing. Now, the first one was how do we migrate APIs? So, the answer is, we use Pact to protect ourselves from backwards compatibility issues. And we try, well we have to do things in a way that is backwards compatible. So you talked about, you update an API, you have to go and change everything that uses it. Well, no. You shouldn’t have to do that. You should update in a way that that doesn’t have to happen. And then you can update the things at whatever pace you want to. You can even leave them using the older version for a year if that’s convenient to you.
(Question about how to maintain the nature of a service a it evolves to ensure it doesn’t grow beyond its initial purpose and turn into a big ball of mud.)
Yes, I talked at the start about how we have one primary responsibility for each artefact and there are sometimes corollary responsibilities. So, that would be something that something naturally does. So as an example, if something was getting a huge batch of payments and then kind of crushing them up into one sort of single settlement message, or something like that, that’ll be its primary responsibility. But then, obviously someone’s going to want to know something about that settlement message. So, it would have the corollary responsibility of reporting on those clearing runs that it’s done or something like that. So I think with your question about adding things over time and that kind of thing, I think you want to be really careful about what’s the primary responsibility and what’s a corollary. You don’t want something with one primary responsibility and 15 corollary responsibilities because that would mean you’re cramming stuff in. And so, I guess you just want people to be challenging each other when they’re talking about adding something into an existing service. Is that really that thing’s responsibility or is that something that something else can be doing? Maybe it can be a group receiving events from that original thing every time it does something and then it can do its thing over there.
Is there another last question?
“You mentioned you want to move from messaging. Where to?”
Feeds. So someone came in and asked me about Rabbit the other day, and I said, ‘Ah, it’d be really nice if someone would try out ATOM feeds and tell us how that works.’ So there’s someone trying that out now. We’ll give that a go. The beauty of that is the components will provide their own feeds so they’re still autonomous in that respect. So anything that needs that feed can connect to it.
(Question about Pact and the data sets it requires and how that data is pre-loaded for a test.)
Yeah, that’s a good question. So the way Pact works is there’s a recorder in your consumer test and it basically records everything you’ve done so it records you did a GET request on this URL with these parameters or if it was a POST it will record the body and then you put in an expected response which will usually be some sort of JSON payload. And it records all of that as a document and there’s actually a thing called a Pact broker which is kind of like Nexus. I don’t know if people know Nexus, the Maven repository. It’s kind of like that but for Pact tests. So you can put your PACT tests into that broker and then, when you your run provider tests, it’s actually pulling those test from the broker and running them from there. And you can put tags on those things. So we’ve basically set up our production things, our producers so that when a producer test runs, it automatically grabs the consumer expectations that are tagged with reproduction, meaning they’re in production now, and LATEST, so the ones that have been the latest to be written. So it’s essentially…
“So if the data’s changing wouldn’t the response change?”
Yes it does. So expectations will change over time. If you’re talking about real data, it’s all test data, so you kind of have to figure out how to…
“Do you have to freeze the data?”
There’s a few different ways of doing it. Some of them are like mocking, where put in really detailed expectations. Some of them are more like a workflow. Why don’t we chat more about it afterwards?
Alright, thanks everyone very much. Thanks for your thoughtful questions.
</transcript>
Image Credits
Creative Commons image credits for the slides:
Honeycomb
Credit cards
Hype cycle
Money
Bees on honeycomb
Parkour Jump
Blueprint
Bouncy balls
American Football players
Mailboxes
Server room with grass
Rock climber
You must be 54″ tall
Baton pass
Class photo
{kind=link}
“You must be this tall to use microservices” image from Martin Fowler’s blog on Microservice Pre-requisites. Used with permission.
“Hype-Cycle-General” by NeedCokeNow – Own work. Licensed under CC BY-SA 3.0 via Wikimedia Commons
{kind=link}
I’m really happy to see this being done at Tyro 🙂 as well as read about the breaking up of the “monolith”.
The microservices world is quite interesting. I’ve worked in a place with over 200 microservices. Provided good monitoring and coding discipline, it’s everything the reactive manifesto looks for and quite easy to extend.
One area I’d like to learn more about is service discovery. The number of services can grow very fast, and it unless you know which one to look for, you can often end up duplicating work that has been done else where. But this is a small concern.
Hi Piyush. Great to hear from you!
I’ve always seen ‘service discovery’ used in the context of services finding each other, but you seem to be using it here in the sense of developers discovering what services are available. Is that right?
I can’t see this becoming a real problem for us any time soon. The reason is because we’re not aiming to create generalised, re-usable services. We’re carving our system up into services that assume autonomous business responsibilities. This means firstly that there is less likely to be cases for re-use of services, and secondly that there will be greater knowledge of what services exist, because they equate to the business responsibilities that have been programmed into the system, and there is generally good enough knowledge sharing that people know what business responsibilities other teams have added to the system.
Does that make sense?
Hi Graham,
Thanks for the transcript, it’s very very interesting. I have a question if you don’t mind ? In your fake architecture diagram, we can see all the services are communicating between each other by using JSON (over HTTP or Message queue, it doesn’t really matter here). That means on one side, you have your domain model, local to your service, probably a POJO, getting serialized and sent to a service. This service will have to deserialize the JSON into another POJO I guess, to be able to use it. How do you guys handle this “shared-domain-model” between services ?
Cheers !
Hi Michael.
Thanks for the question. It’s a good one.
In the past we used Spring Remoting for most inter-process comms (it’s like a Spring version of RMI), and we’ve continued with a pattern that we’ve always used with that: API projects. So, each API offered by a service has a corresponding API project, as do the messages sent along Rabbit.
With Spring Remoting, the API project contained the interfaces exposed on the server and called from the client, and the DTOs and value objects used in the interface. With REST and Rabbit, the interface is defined by the underlying protocol (HTTP and AMQP, respectively), so the API project just contains the DTOs and the value objects. In the REST case, the DTOs equate to the JSON bodies being received or returned by the server, and in the Rabbit case they equate to the message body sent and received. Rabbit APIs might also contain the relevant exchange, queue and key names as constants. This allows us to use GSON conversion (serialisation/deserialisation) on each end quite simply, without writing custom mapping code or duplicated POJOs at each end. At the same time, we’re still presenting a language agnostic interface in case we at some point decide to create a REST client or server or message producer or consumer that isn’t JVM-based and hence can’t leverage the API.
It’s responsible of me to mention at this point that, when you change the contract of the server, you need to be aware of backwards compatibility. Sharing DTOs doesn’t make this any worse, but it could give the illusion that you don’t need to worry any more, because the client and server share the API code. However, unless you deploy all instances of the server and the client at exactly the same time (and you generally don’t want to be doing that with MSA), you will need to make sure that your new version of your server, using the new version of the DTOs and value objects, still supports all of the contacts required by clients using the old versions of these, because when you deploy server version +1, the old clients will still be running and you want them to work. This is where Pact comes in: allowing you to execute the contractual expectations of older clients as tests against the newer versions of the server.
Cheers,
Graham.
Pingback: Is a Microservices PaaS In Our Future? - Evolvable Me
Hi Graham
Just finished reading the transcript. Great information and looks like things are working well using micro services.
I was just wondering if there is any further progress on ATOM feeds and how they compare to RabbitMQ for messaging. Do they avoid the single point of failure problem?
Also wondering if service discovery is being used in terms of the services discovering each other.
Thanks
Pingback: Microservices Security: All The Questions You Should Be Asking - Evolvable Me
Pingback: "This work kinda sucks": Staying motivated in the uninspiring phases of long projects - Evolvable MeEvolvable Me
Pingback: How to Choose Your First Microservices • Evolvable MeEvolvable Me